讓電腦聽懂人話: 直觀理解 Word2Vec 模型
自然語言處理 (Natural Language Processing) 是近年來在機器學習領域取得重大進展的應用之一,除了歸功於進 5–10 年來資料量的大幅增加與運算能力的提升外,Word2Vec 模型可以說是扮演極為重要的角色。Word2Vec 是 Google 於 2013 年由 Tomas Mikolov 等人所提出,透過學習大量文本資料,將字詞用數學向量的方式來代表他們的語意。並將字詞嵌入到一個空間後,讓語意相似的單字可以有較近的距離。
本文則試著透過比較直觀,不使用到數學公式的方式,來理解 Word2Vec 模型。
Word2Vec 模型中,主要有 CBOW 與 Skip-gram 兩種模型。從直觀上來理解, Skip-gram 是給定輸入字詞後,來預測上下文;CBOW 則是給定上下文,來預測輸入的字詞。本文僅說明 skip-gram 模型。

從一個字詞,到產生這個字詞的詞向量,再到預測其他可能會在那個字詞附近出現的詞彙的機率
舉例來說,輸入一個詞彙 “wine”,則模型訓練產生的結果,可能會預測在 “wine” 附近有較高機率出現的字是 “grape”, “Bordeaux”,而一些字詞像是 “NLP”, “AI” 可能出現的機率就會比較小。至於怎樣算是 “wine” 這個字的「附近」呢?我們則可在訓練模型時定義一個範圍,比如說在一句話中,”Wine” 的前後 5 個字都算是她的附近,這個範圍,我們稱為 “window size”
因此,我們在這邊的任務就是訓練一個神經網路,可以在給定一段句子中的一個字詞後,他告訴我們其他字詞出現在那個字附近的機率是多少。以下用一個範例來解釋我們如何產生訓練樣本,假設我們給定一個訓練文本:
The quick brown fox jumps over the lazy dog.並將 window size 設定為 2,圖二中用藍色標起來的字詞為輸入的詞彙,則 “the” 這個字可以產生 (the, quick) 和 (the, brown) 這兩對訓練樣本;”quick” 這個字則可產生 (quick, the), (quick, brown), 及 (quick, fox) 這三個訓練樣本。

我們訓練的神經網路就會開始去統計每個成對的詞彙出現的次數。所以,舉例來說,比起 (wine, NLP),可能會有較多的 (wine, grape) 或 (wine, Bordeaux) 這樣的詞組,因此,當神經網路訓練完後,給定一個輸入字詞 “wine”,比起 “NLP”,”grape” 或 “Bordeaux” 可能會有更高的機率出現在他附近。
將字詞用向量來表示
因為我們沒辦法直接把文字輸入機器讓他做辨識,必須要將他轉成向量的方式,機器才有辦法做數學的運算。最常見的方式,就是建立出一個詞彙表後,然後用 one-hot 編碼。假設我們可以從訓練文檔中抽取出 10,000 個不重複的單詞,組成詞彙表,那每一個詞彙就會是一個用 0 和 1 兩個數字表示的 10,000 維的向量。比如說 “ants” 這個字在詞彙表中出現的位置是在第 3 個位置,將 “ants” 用 one-hot 向量編碼表示後,他就會是一個第三個維度為 1,其他維度為 0 的一個 1 x 10,000 的向量。
ants = [0, 0, 1, 0, 0….,0]而神經網路的輸出層也會是一個 1 x 10,000 的向量,包含我們詞彙表中的每一個字詞,以及這個字詞出現的機率。下圖為這個神經網路模型的示意圖。

當用神經網路來訓練成對字詞出現的模型時,輸入層是一個 one-hot 編碼表示的 1x10,000 的向量,輸出層也會是一個相同維度,用 one-hot 編碼來表示的 1x10,000 的向量,但當我們用輸入字詞來評出模型時,他會轉換成機率分佈,用來表示每個字詞出現在輸入詞附近的機率。
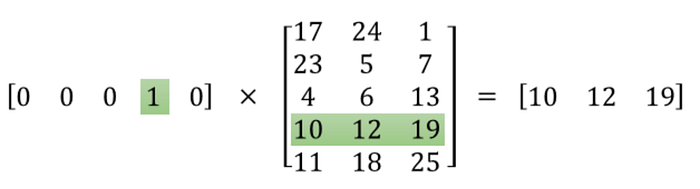
我們也可以來看一下所訓練的神經網路,在圖三中隱藏層 (hidden layer) 的部分,在論文中,Google 使用了 300 個 features,讓這個神經網路變成了一個 10,000 rows x 300 columns的矩陣。而這個模型的目標,就是計算出隱藏層中這個 10,000 x 300 的矩陣中的的值。10,000 x 300 有點太大,我們用下面圖四當作範例的話, [0 0 0 1 0] 這個 1 x 5 的向量可以當作是 one-hot 編碼過後的字詞,而中間那個 5 x 3 的矩陣,就是神經網路訓練出來的結果,他是一個 5 x 3 的矩陣,也就是使用了 3 個 features。我們也可以發現一件有趣的事情是:因為 one-hot 編碼只有一個維度會是 1,其他皆為 0,所以輸出層基本上就是去查是 1 的那個維度,相對應於隱藏層中那個 row,而最後向量相承的結果 [10 12 19],是一個 1 x 3 的向量,我們就把它稱為是輸入字詞的詞向量 (word vector),套回 10,000 x 300 的矩陣的例子的話,這邊我們會得到一個 1 x 300 的向量,用來代表我們輸入的那個字。(所以 word2vec 就是這樣來的!)
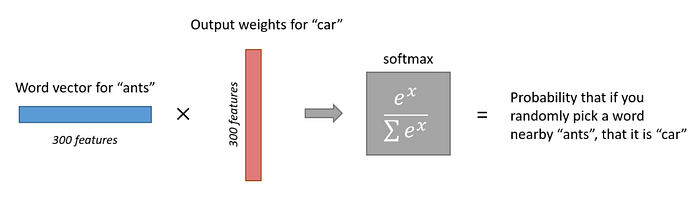
到此為止,我們可得到一個 1 x 300 的向量,然後餵進輸出層。在輸出層中,將詞向量與某個我們感興趣的字詞的輸出權重相乘,即可得到一個值,然後再經由 Softmax Regression 函數,將這個值轉換成一個介於 0–1 的數字,代表他出現的機率。圖五即用輸入詞為 “ants”,輸出詞為 “car” 出現的機率作為範例,輸出層的示意圖:
透過一些技巧提高訓練模型的效率
問題是,如果用前述的例子來訓練一個 10,000 x 300 的神經網路的話,我們必須要計算這個矩陣中,共三百萬個權重的值!因此,這篇論文提出了三個方式來提高模型的訓練效率:
- 在模型中,將常見的單詞組合 (word pairs),或是詞組 (phrase) 當作是單個字來處理
- 對高頻率出現的字詞進行抽樣,來減少訓練樣本的數目
- 對於優化目標,使用 “Negative Sampling” 的方式,讓每個訓練模型,可以只更新一小部分的權重,降低運算的負擔
值得一提的是,第 2 和第 3 點,不但降低了運算的負擔,也提高了訓練出的詞向量的品質。
某些單詞的組合,例如 Boston Globe,是個週刊的名字,他和單獨用 Boston,或 globe 表示的詞彙差異很大,因此我們應該把它當作是一個詞彙來生成詞向量,而不是拆開來處理。相同的例子也可以用在 “New York” 和 “United States” 上。
我們回去看圖二,用 “The quick brown fox jumps over the lazy dog.” 這個句子來舉例,對於高頻率出現的單詞,比如說 “the”,他會產生兩個問題:
- 像 (“fox”, “the”) 這樣的單詞組合幾乎不會對 “fox” 這個詞提供任何語意相關的訊息,因為 “the” 太常出現了,許多名詞的前面都會有他
- 因為 “the” 的數目太多,所以我們會產生大量 (“the”, “XXX”) 的訓練樣本,而這些樣本的數目可能遠超過我們學習 “the” 這個詞向量所需要的訓練樣本數
這邊,word2vec 用抽樣 (subsampling) 的方式來解決像 “the” 這樣高頻率單詞所造成的問題。對於文本中所看到的單詞,他們有機會會被刪掉不被考慮,而被刪除掉的機率與他們出現的頻率有關。
舉例來說,如果我們將 widow size 設為 10,並且將 “the” 從文本中移除,則:
- 在訓練樣本中,“the” 再也不會出現在上下文的選取範圍中
- 至少可以減少 10 個訓練樣本
訓練一個神經網路必須輸入訓練的樣本,然後不斷地更新神經元的權重,進而提高對目標的預測,每經過一個訓練樣本的訓練,各個神經元的權重就要進行一次調整。假設我們詞彙表中有 10,000 個字詞,形成一個龐大的神經網路,那每有一個訓練樣本,就要重新調整一次,這將耗費龐大的運算資源,也會讓實際模型訓練起來非常的慢。
Negative sampling 即用來解決這個問題,對於每個訓練樣本,只更新一部分的權重,而非整個神經網路的權重都被更新。舉例來說,當我們用訓練樣本 (input word: “fox”, output word: “quick”) 來訓練我們的神經網路時,”fox” 和 “quick” 都是用 one-hot 編碼來表示。如果我們詞彙表的大小是 10,000 的話,則在輸出層,我們期望對應 “quick” 這個字詞的神經元節點輸出是 1,其他 9.999 個神經元輸出都是 0,這 9,999 個期望輸出為 0 的神經元節點所對應的字詞我們就稱為 “negative word”。
當使用 negative sampling 時,我們隨機選擇一小部分的 “negative” words (比如說選 5 個 negative words) 來更新相對應的權重。我們也會針對 “positive” word 做更新,在目前的例子,positive word 是 “quick”。論文中是說如果是小規模數據集的話,可選 5–20 個字作為 negative sample;但對於比較大的數據集的話,可選擇 2–5 個字詞作為 negative words。
在圖三的例子中,我們的輸出層是一個 300 x 10,000 的權重矩陣。如果我們只更新 “quick” 這個 positive word,以及其他 5 個 negative words 的權重的話,總共只需要更新 6 個神經元,也就是 6 x 300 = 1,800 個權重,只有原本的 0.06%,大幅提高計算的效率!
Negative sampling 的好處是,透過隨機取樣的方式,降低錯誤信號對整體模型造成的影響。如果我們再次以 ”The quick brown fox jumps over the lazy dog.” 作為文本範例,若輸入字詞是 brown,window size 設為 2 時,(brown, dog) 會被視為 negative sample,那 model 學到的就會是「brown 這個字的周遭不該出現 dog」這樣的信號。然而,這個信號明顯不是正確的,也會把 model 帶往錯誤的方向,大部分被我們當作 negative 的字,其實只是不在 “unobserved”。透過 negative sampling 隨機取樣的方式,希望把他們的權重降低一點,希望可以降低錯誤信號的影響。
